Meet AdaCL, A Plug-in for Smarter and Memory-Efficient Continual Learners.
Elif Ceren Gok Yildirim, Murat Onur Yildirim, Mert Kilickaya, Joaquin VanschorenHello, everyone! Today, I’m thrilled to introduce you to our recent work: AdaCL, which stands for Adaptive Continual Learning. This innovative approach is not only straightforward but also incredibly versatile, making it easy to implement across various frameworks. Let's dive in and explore what makes AdaCL so exciting!
Understanding Class-Incremental Learning
- In the rapidly evolving field of artificial intelligence, one of the key challenges is enabling models to learn continuously without forgetting previous knowledge. This concept, known as Class-Incremental Learning (CIL), aims to update AI models with new categories while maintaining or even improving accuracy on previously learned classes. However, traditional methods often fall short due to their inability to adapt dynamically to new tasks.
- Class-Incremental Learning is a paradigm where a deep neural network is updated with new data that arrives sequentially. Unlike standard batch learning, which requires access to all data categories simultaneously, CIL allows the model to expand its classifier with new output nodes for newly introduced classes. This method avoids the need to store task identities, creating a more efficient and realistic learning scenario. However, a significant challenge in CIL is catastrophic forgetting. This occurs when a model sacrifices accuracy on previously learned classes to learn new ones. Researchers have developed various approaches to mitigate this, including regularization, replay, and architecture adaptation.
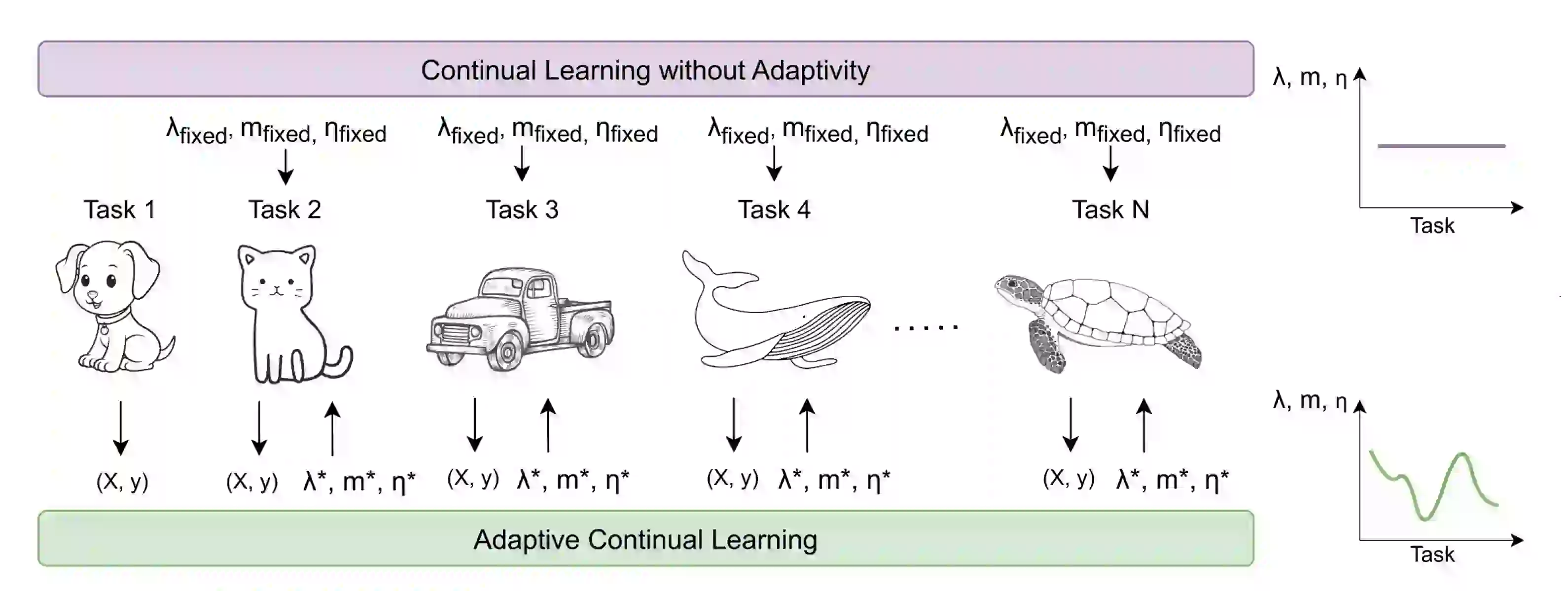
The Need for Adaptive Learning
- Traditional CIL methods typically use fixed hyperparameters—such as learning rate, regularization strength, and memory size—throughout the learning process. This approach can be limiting because different tasks may require different levels of plasticity and stability. For instance, learning an unfamiliar object might require more flexibility compared to a familiar one. This is where AdaCL steps in. We propose a way to dynamically adjusting hyperparameters based on the current state of the learner and the complexity of the new task. By leveraging Bayesian Optimization, AdaCL efficiently determines the optimal values for these parameters, enhancing the model's ability to learn new tasks while retaining previous knowledge.
AdaCL: A Versatile Plug-in
- One of the standout features of AdaCL is its versatility. AdaCL is designed as a plug-in method, meaning it can be integrated with any existing CIL method. This adaptability ensures that various CIL approaches can benefit from the dynamic hyperparameter tuning provided by AdaCL, leading to enhanced performance across different applications.
How AdaCL Works
- AdaCL focuses on three main hyperparameters:
- Learning Rate (η): Controls how much the model learns and update its weights during training.
- Regularization Strength (λ): Prevents changing the model too much not to forget previously acquired knowledge.
- Memory Size (m): Determines the number of exemplars stored from previous tasks for replay.
In AdaCL, these hyperparameters are treated as latent variables, adjusted dynamically with each new learning task. This adaptivity is achieved through Bayesian Optimization, a powerful technique that efficiently explores the hyperparameter space to find the optimal settings.
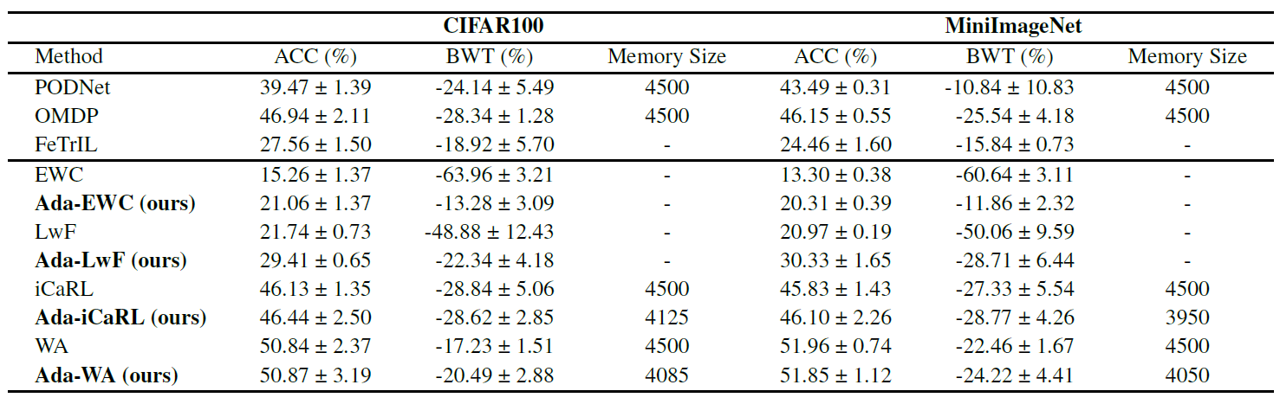
Experimental Success
- AdaCL's effectiveness has been demonstrated through extensive experiments on well-known benchmarks like CIFAR-100 and MiniImageNet. The results showed significant improvements in accuracy and a reduction in forgetting, highlighting the benefits of adaptive hyperparameter tuning in CIL. Notably, AdaCL achieved the same accuracy while storing less replay data from each task, showcasing its efficiency and potential for real-world applications.
Key Contributions of AdaCL
- Introduction of Adaptive Hyperparameter Selection: AdaCL is the first to highlight the importance of adaptive hyperparameter tuning in class-incremental learning. By predicting optimal values for learning rate, regularization strength, and memory size based on the current task and learner state, AdaCL sets a new standard in CIL.
- Performance Improvements: Large-scale experiments confirmed that AdaCL significantly enhances performance by whether increasing accuracy and reducing forgetting, or storing less exemplars and consuming less memory.
- Versatile Plug-in Method: AdaCL can be integrated with any CIL method, enhancing its utility and flexibility.
Conclusion
AdaCL represents a significant advancement in the field of adaptive continual learning. By dynamically tuning critical hyperparameters, AdaCL enables AI models to learn new tasks more effectively while preserving previously acquired knowledge. This approach not only improves the performance of AI models but also paves the way for more robust and adaptable artificial intelligence systems.
As AI continues to evolve, methods like AdaCL will be crucial in developing systems that can continuously learn and adapt to new information, much like the human brain. This breakthrough underscores the importance of adaptability in AI and sets the stage for future innovations in the field.
If you are interested, you can dive deeper and check out the paper and the code.